Paper Summay on Aligning LLM with Self-Instruct
The paper “Self-Instruct: Aligning Language Model with Self Generated Instructions” introduces a framework called Self-Instruct for improving the instruction-following capabilities of pretrained language models by bootstrapping off its own generations. The framework generates instruction, input, and output samples from a language model, then prunes them before using them to finetune the original model, which results in a significant improvement in model performance.
Key Insight
Key insights and lessons learned:
-
The Self-Instruct framework achieves comparable performance to the InstructGPT_001 model, which is trained with private user data and human annotations, on the Super-NaturalInstructions dataset.
-
Tuning GPT3 with Self-Instruct outperforms using existing public instruction datasets, as demonstrated through human evaluation.
Core Method
The key method proposed in the paper is a self-instruct data generation process. There are 4 kinds of prompt-template prepared as following
-
Generating the instruction (Table 6 in paper)
-
classifying whether an instruction represents a classification task or not (T7)
-
generating non-classification instances with the input-first approach (T8)
-
generating classification instances with the output-first approach (T9)
They are feed in to following workflow.
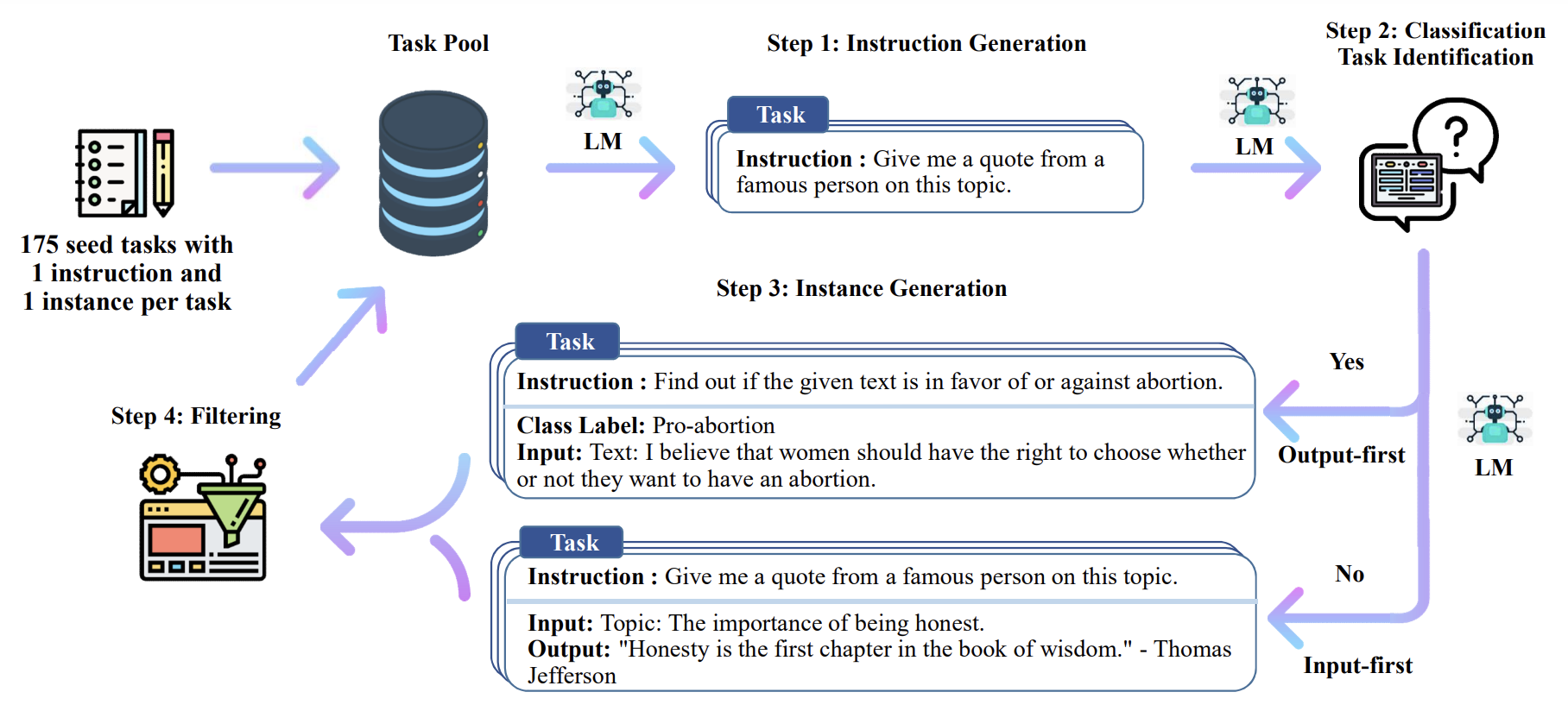
Finally, the ROUGE-L will be used for filtering step. To encourage diversity, a new instruction is added to the task pool only when its ROUGE-L overlap with any existing instruction is less than 0.7. Authers also exclude instructions that contain some specific keywords (e.g., images, pictures, graphs) that usually can not be processed by language models. When generating new instances for each instruction, we filter out instances that are exactly the same or those with the same input but different outputs.
The fine-tunning process is in supervise-learning method.