Modeling Uncertainty of ML Systems (01)
For model productization, evaluating the efficacy of the ML system is essential. In pratical, we usually leverage a series of methods to model the efficacy or uncertainty. It is a big topic and this memo will only talk about 4 types of uncertainties as illustraion. These 4 types of uncertainty are composed by Aleatoric vs Epistemic and Homoscedastic vs Heteroscedastic
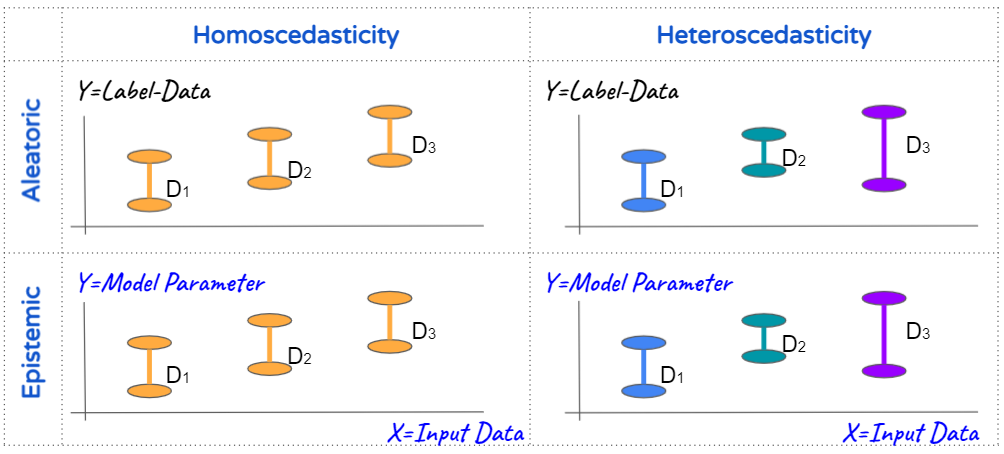
Aleatoric and Epistemic
From the source perspective, the uncertainty can be categorized into Aleatoric and Epistemic uncertainty.
Aleatoric uncertainty captures noise inherent in the observations / raw data. It describes randomness arising from the data generating process itself. This noise that can Not be eliminated by simply drawing more data. In pratical, the inconsistance of labeling data is one of the biggest contribution to aleatoric uncertainty.
Epistemic uncertainty accounts for uncertainty in the model parameters. It is more likely to see if we have over-parameterized model or we dont have enough data. Intuitively, It could be reduced by have more data or decreasing the model parameters. Widely speaking, I am considering any method to prevent overfitting could potentially reduce the epistemic uncertainty.
Variational inference is one of advanced solutions to reduce this uncertainty, like Monte Carlo (MC) dropout or Boostraped Ensemble Model.
Homoscedastic and Heteroscedastic
From another perspective, the uncertainty itself could be homogeneous or heterogeneous with respect to the input $X$. Homoscedastic uncertainty describe the value of uncertainty is a constant for different inputs. On the other hand, heteroscedastic uncertainty means with some inputs potentially it would have more noisy outputs than others.